Autonomous Fault Detection, Isolation and Recovery in OnBoard Computers
- June 9, 2026
- CAVU Aerospace UK
How we build resilient space computing through layered FDIR?
Spacecraft onboard computers must continue operating in an environment where radiation effects, communication interruptions, power disturbances, memory corruption, and hardware faults are expected rather than exceptional. For this reason, the OBC-Hyper-Polar developed by Cavu Aerospace as a case study incorporates a comprehensive Fault Detection, Isolation and Recovery (FDIR) architecture designed to maximise mission availability while minimising dependence on ground intervention.
The OBC-Hyper-Polar employs a layered FDIR strategy that combines hardware protection, redundant subsystems, error-correcting memory technologies, watchdog supervision, autonomous failover mechanisms, and software recovery procedures. Together, these capabilities allow the system to detect anomalies, isolate failed components, and restore operational capability automatically.
Power System Recovery
The first line of defence against electrical faults is implemented at the power input stage. DC/DCs are usually most critical part in FMEA sheets!
Dual electronic fuse (eFuse) circuits continuously monitor input voltage and current conditions. In the event of over-voltage, excessive inrush current, or radiation-induced latch-up events, the affected power path is automatically isolated through current-limited foldback protection. Once the fault condition clears, the controller can safely retry power application using a controlled current ramp.
For the primary 5 V power rail, the OBC-Hyper-Polar incorporates redundant DC-DC converters operating with branch protection. If one converter experiences regulation failure or under-voltage conditions, the redundant converter automatically assumes the load while the failed branch is electrically isolated. This architecture prevents single-point failures from propagating into the spacecraft avionics network.
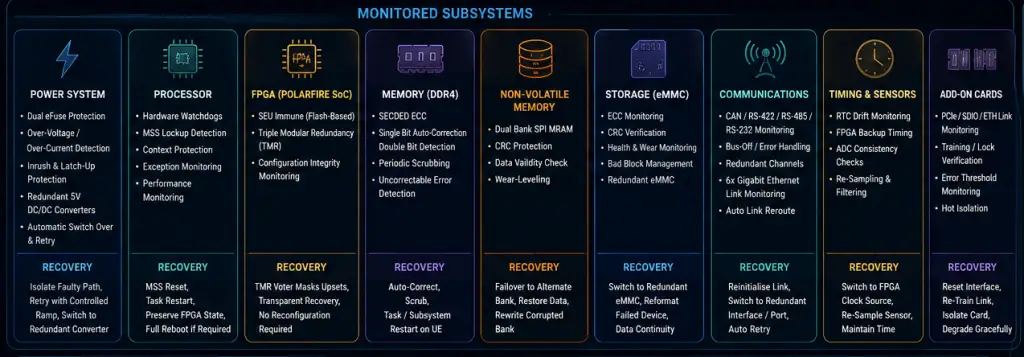
Processor Recovery Through Hardware Watchdogs
At the heart of the system is the Microchip PolarFire SoC, comprising multiple application processors and a supervisory monitor core.
Software execution anomalies, radiation-induced single-event upsets (SEUs), or processor lockups are detected using hardware watchdog timers. If an application processor ceases normal execution, the watchdog automatically expires and initiates recovery.
Rather than requiring a full system reboot for every anomaly, the architecture supports targeted recovery of the Microprocessor Subsystem (MSS). The MSS can be reset while preserving the operational state of FPGA fabric resources where mission-safe conditions permit. Event information is retained and logged for post-event analysis.
This capability enables rapid restoration of functionality while reducing disruption to spacecraft operations.
FPGA Logic Resilience
Unlike SRAM-based FPGA technologies, the PolarFire FPGA fabric utilised within the OBC-Hyper-Polar is flash-based and inherently resistant to configuration upsets.
As a result, configuration memory scrubbing is not required. Critical logic functions are further protected through Triple Modular Redundancy (TMR), where multiple logic replicas operate simultaneously and voter circuits identify discrepancies.
When a transient upset affects one logic path, the voter automatically masks the error and maintains correct system operation. Recovery therefore occurs transparently without interrupting spacecraft activities.
Memory Error Detection and Recovery
Volatile memory resources are protected using SECDED (Single Error Correction, Double Error Detection) Error Correcting Code technology.
Single-bit memory upsets caused by radiation are corrected automatically during normal operation without software intervention. Periodic memory scrubbing further reduces the accumulation of latent errors.
When an uncorrectable memory event is detected, recovery actions are escalated according to severity. The affected software task may be restarted, or a controlled subsystem reset may be initiated to restore a known-good operational state.

Non-Volatile MRAM Recovery
Mission-critical state information is stored within dual-banked SPI MRAM devices.
Each record is protected using cyclic redundancy checks (CRC). If corruption is detected, the system automatically reads the alternate bank and restores valid data. Corrupted records are subsequently rewritten during housekeeping activities.
The use of MRAM provides exceptional endurance and ensures reliable state retention throughout long-duration missions.
Autonomous Storage Failover
Mission data storage is implemented using redundant eMMC devices.
The storage controller continuously monitors ECC statistics and application-level CRC verification results. If excessive errors or corruption are detected, the OBC automatically redirects operations to the redundant storage volume.
The failed volume can later be reformatted and restored during an appropriate maintenance window, enabling continued mission operations without data service interruption.
Similarly, boot images are stored across redundant QSPI flash devices. During startup, each image undergoes SHA-256 integrity verification. If corruption is detected, the bootloader automatically selects the redundant image and continues system startup. Known-good images cached in MRAM can subsequently be used to restore corrupted flash devices.
Communication Link Recovery
Spacecraft communications often represent mission-critical functions and are therefore protected through multiple layers of redundancy.
The OBC-Hyper-Polar supports redundant CAN, RS-422, RS-485 and RS-232 interfaces. Communication controllers monitor CRC failures, framing errors, and protocol-specific fault conditions. When a communication channel enters an error-passive or bus-off state, traffic is automatically redirected to a redundant channel and periodic recovery attempts are initiated.
For high-bandwidth networking, the platform provides a six-port Gigabit Ethernet architecture. If a physical Ethernet link fails or exceeds error thresholds, traffic is automatically rerouted to an alternative port within the available Ethernet pool. Link renegotiation and health monitoring occur continuously in the background.
Add-On Card Fault Isolation
The modular architecture of the OBC-Hyper-Polar supports expansion through a high-speed add-on card interface which can improve interface capability to several Gb Eth, Serial etc.
The system continuously monitors PCIe training status, SerDes lock conditions, SDIO integrity, and Ethernet connectivity. If a persistent interface failure is detected, the add-on card can be logically isolated while the primary onboard networking resources continue operating.
This capability prevents expansion hardware failures from affecting core spacecraft computer functions.
Sensor and Timing Recovery
Analogue acquisition channels employ cross-validation and statistical consistency checks. Suspect measurements trigger automatic re-sampling and filtering procedures before faults are declared.
For timing functions, the real-time clock is continuously supervised. If clock drift, loss of tick progression, or oscillator failure is detected, the system automatically transitions to an FPGA-based timing source and maintains spacecraft timekeeping until synchronization can be restored.
A Layered Recovery Philosophy
The FDIR architecture of the OBC-Hyper-Polar follows a fundamental principle in design: RECOVER LOCALLY WHENEVER POSSIBLE AND ESCALATE ONLY WHEN NECESSARY!
Most faults are corrected transparently through ECC mechanisms, TMR logic, redundant hardware resources, or automatic failover procedures. More severe anomalies invoke subsystem resets, storage recovery, communication rerouting, or safe-mode transitions. This layered approach minimises operational interruptions and maximises mission availability.
By combining radiation-tolerant hardware, autonomous recovery mechanisms, and comprehensive fault management, the OBC-Hyper-Polar provides spacecraft integrators with a highly resilient computing platform capable of sustaining reliable operations throughout demanding orbital missions.
